Kubeflow SDK를 이용한 파이프라인 업로드 및 빌드
kubeflow SDK를 이용해 pipeline에 접속하는 방법은 크게 envoy filter 활용과 poddefault를 이용하는 방법 2가지가 있다.
1. Envoy filter를 통한 인증 우회
kubeflow namespace ML pipeline 서비스에 대한 요청이 default editor에 존재하는 지 확인하도록 authorization policy를 적용한다.
또한 kubeflow user example.com namespace에서 ml pipeline 서비스로의 요청에 대해서는 envoy filter를 이용해 kubeflow user ID에 대한 header를 추가하여 인증을 우회함
header에 추가하는 내용은 default editor service account를 통해 확인이 진행됨
---
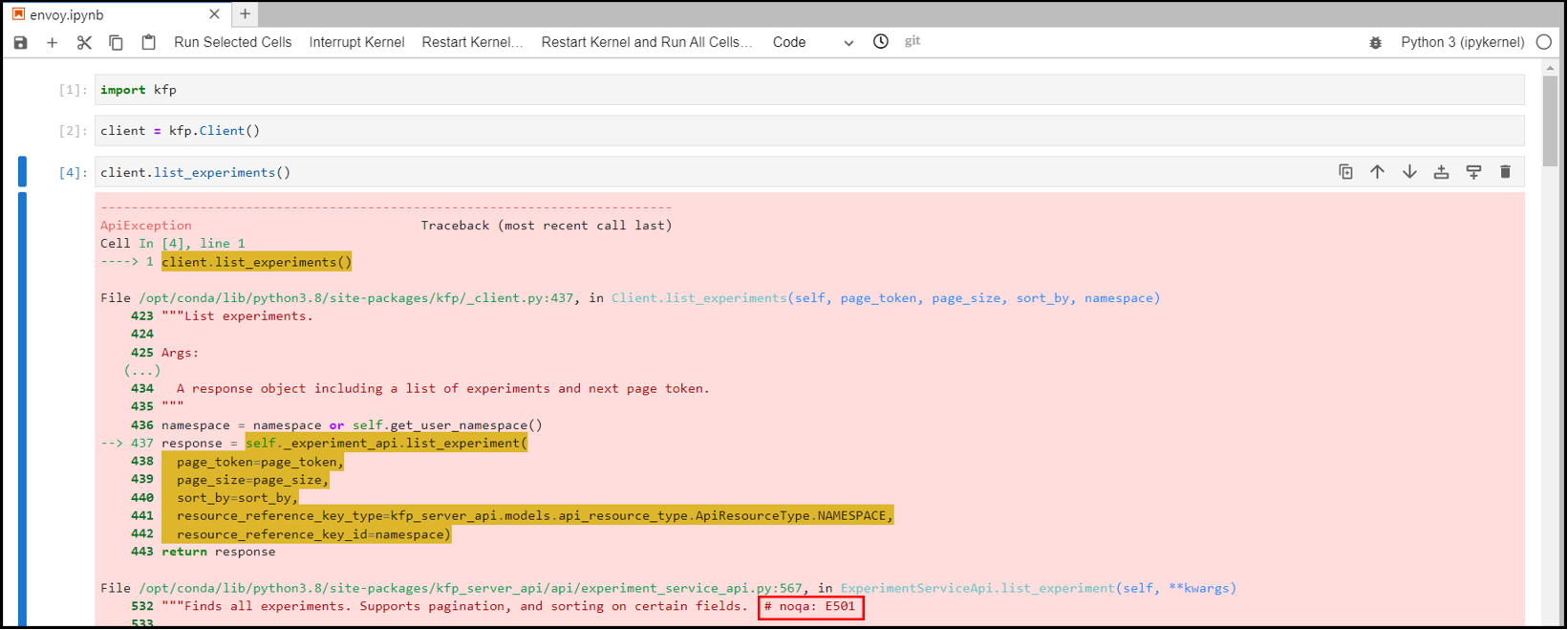
SDK를 이용해 pipeline에 접속했는 지 확인할 수 있는 방법은
Kubeflow client 객체를 생성하고, list_experiments()를 이용하는 것이다.
인증이 진행되지 않았을 때 Error message(500)가 발생하는 걸 확인할 수 있다.
이제 Envoy filter를 적용하기 전, Authorization policy를 정의한다.

$ kubectl apply -f AuthorizationPolicy.yaml
이후 envoy filter는 notebook terminal에서 적용해줘야 한다. 먼저 다음 파일을 생성한다.

이후 kubectl apply 명령어를 통해 적용 후, 확인해보면 EnvoyFilter가 생성된 것을 확인할 수 있다.

이후 notebook에서 experiment를 확인해보면, kubeflow pipeline experiment에서 확인했던 내용을 볼 수 있다.

2. Poddefault를 사용한 Token 저장
kubeflow의 custom resource로 생성되는 pod의 default 값을 설정 가능
따라서 notebook 생성 시, token 값을 저장하는 paddefault object를 만들 수 있다.
---
노트북 생성 시 token을 저장하는 yaml 파일을 만들고, token을 이용해서 인증을 진행할 수 있다.
pod default는 kubeflow의 custom resource다. 그래서 생성되는 pod에 기본값을 지정할 수 있도록 만들어주고 있다.
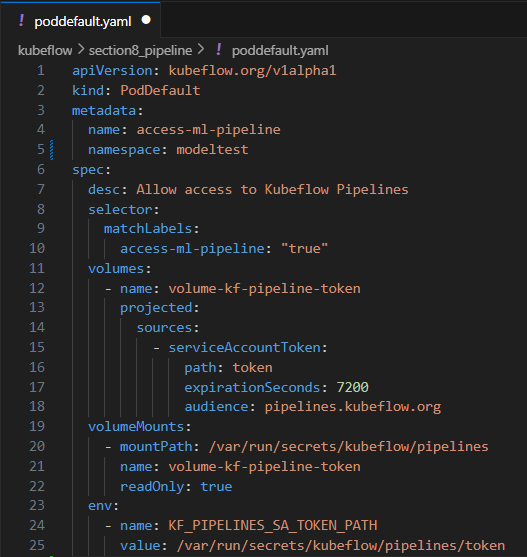
$ kubectl apply -f poddefault.yaml
poddefault는 notebook 생성 시 적용되기 때문에, 우리가 notebook을 새로 생성해주어야 한다.
Notebook 생성 과정 중, configurations를 보면, poddefaiult로 생성한 tab이 있는 걸 볼 수 있다.

이후 notebook 실행 후 다음 코드를 실행하면, experiments를 확인할 수 있다.
기존 PV에 binding시켜서 진행하면, 적용 안됨에 주의한다.

3. SDK를 활용한 Create component
이제 experiment를 custom하게 짠 후 Run details를 확인해보면, pipeline이 성공적으로 돌아가는 것을 확인할 수 있다.

4. SDK를 활용한 Add component
방식은 이전과 동일하다.
함수 정의 후 operator로 만든 뒤, opeator로 pipeline을 만들고 pipeline을 업로드하는 방식을 취한다.
from kfp.components import create_component_from_func
import kfp
from kfp import dsl# 1. Create a python function
# output으로 두 수의 합을 출력해주는 함수
def add_component(a: float, b: float) -> float:
'''Calculates sum of two arguments'''
print(a, '+', b, '=', a + b)
return a + b
# component 생성 시 base image 지정할 수 있음
BASE_IMAGE = "python:3.7"
add_op = create_component_from_func(add_component,
base_image=BASE_IMAGE)
# pod setting
def pod_defaults(op):
return op.set_memory_request('10Mi').set_cpu_request('10m')# 2. Build a pipeline using the component
# pipeline의 이름은 Calculation pipeline
@dsl.pipeline(
name='Calculation pipeline2',
description='A toy pipeline that performs arithmetic calculations.'
)
def calc_pipeline(
a: float =0,
b: float =7
):
add_task = pod_defaults(add_op(a, 4)) # 1st task
add_2_task = pod_defaults(add_op(a, b)) # 2nd task
add_3_task = pod_defaults(add_op(add_task.output, add_2_task.output)) # 3rd task
# 0과 7을 입력받아 각각의 operator를 수행하는 과정을 task라고 한다.# arguments = {'a': '7', 'b': '8'}
arguments={}
EXPERIMENT_NAME = 'lab1-add pipeline'
kfp.Client().create_run_from_pipeline_func(calc_pipeline,
arguments=arguments,
experiment_name=EXPERIMENT_NAME)
위 코드를 차례대로 실행하면, Run details를 확인할 수 있다.
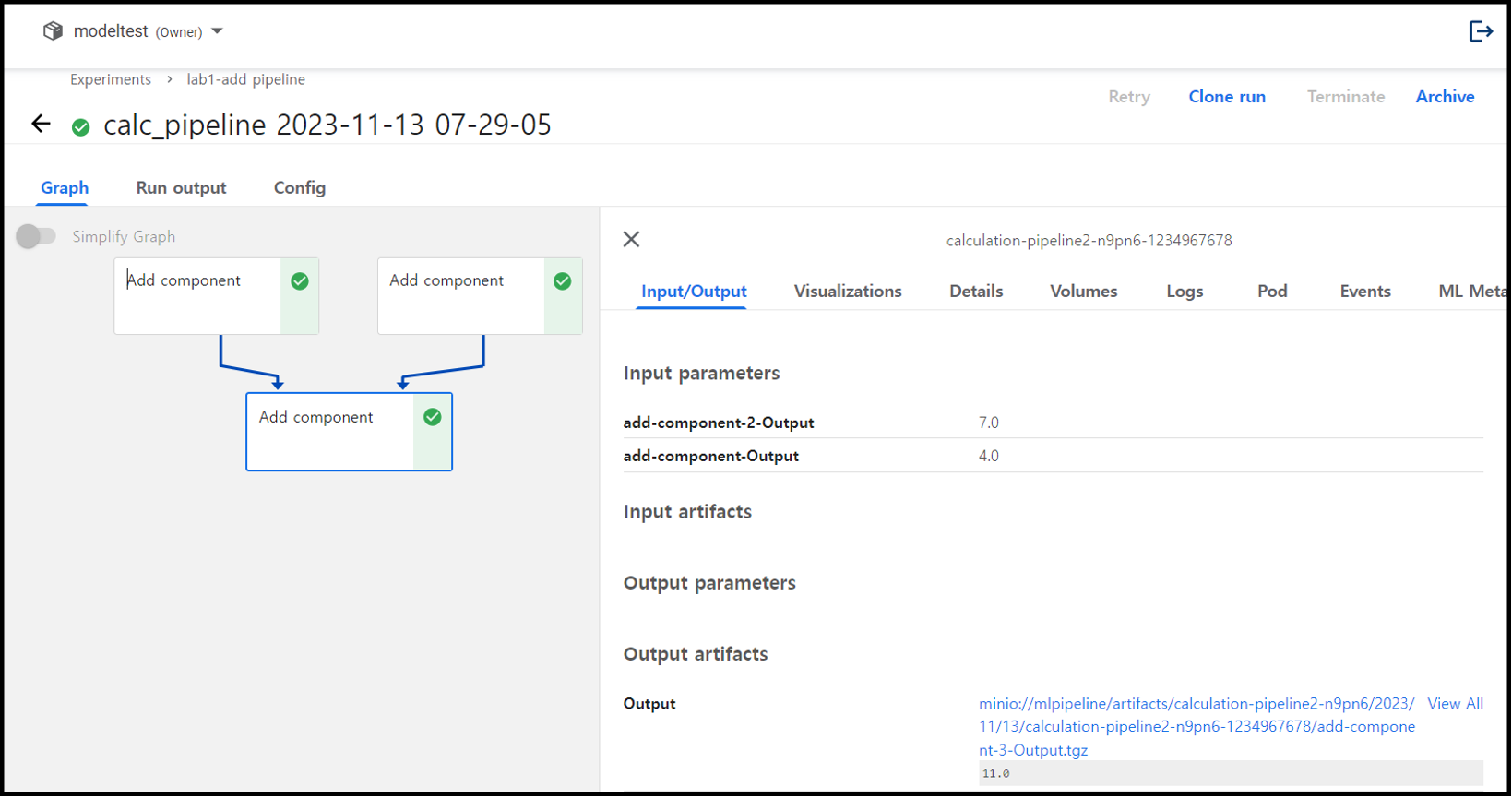
추가로 값을 임의로 넣고 싶다면, 위의 코드처럼 arguments를 dictionary type으로 지정하면 pipeline 실행 시 default로 지정한 값을 무시하고 argument 값이 보내진다.