ML Pipeline 단계
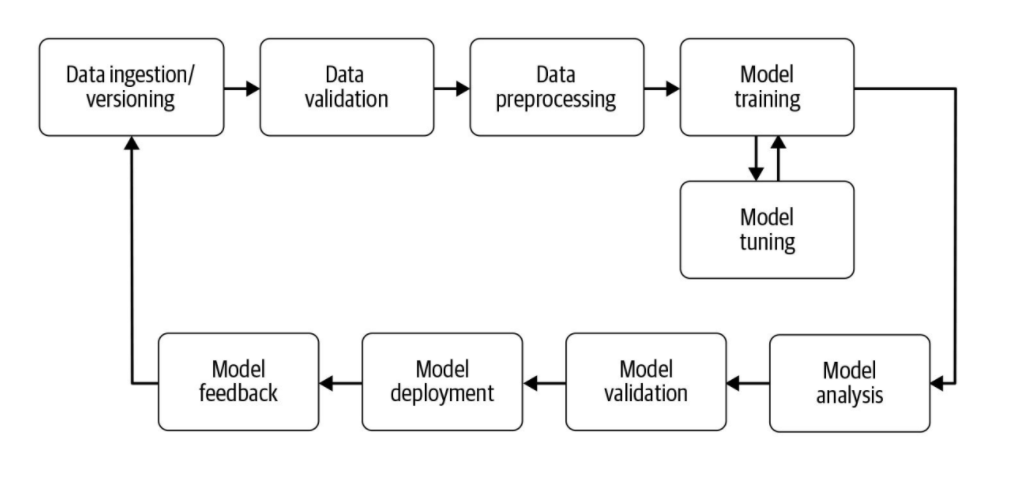
1. Data Ingestion / Versioning
- 다음 구성 요소가 소화할 수 있는 형식으로 데이터를 처리
- 데이터 수집단계에서는 Feature Engineering을 수행하지 않음 (데이터 유효성 검사 단계 후에 수행)
데이터 엔지니어링 관점에서, 우리가 원하는 형태의 데이터셋이 어떻게 생겼는 지 그려본 다음, 원천 데이터로 어떻게 얻어낼 지(이런 데이터를 모으려면, 어떤 로그가 있어야 하는 지~)를 역으로 설계해야 편리하다. (리버스 엔지니어링)
Versioning이 중요한 이유 중 하나는 Reproducibility 때문이다.
Versioning 시, 요즘 회사들은 거의 Cloud 기반이니, 보통 Amazon S3나 GCS, Blobs 같은 Object Storage를 많이 사용
이점은 Data Drift 확인, 바뀐 Data의 Validation도 가능하고, 학습 pipeline에서 어떤 version을 썼다고 로그를 남겨놓으면 재사용이 가능
Dataset Injestion 시 Query마다 데이터가 달라질 수 있다. -> Serialize해서 Object Storage에 담아두는 형태가 비용적인 면에서도 중요
2. Data Validation
- 새 모델 버전 학습 전, 데이터 검증이 필요
- 해당 작업은 새 데이터의 통계가 예상대로인 지 확인하는 데 초점을 맞춤
- 이상 징후 감지 시, Data Scientist에게 Warning Message 날림
현대 이 작업에서 TFDB가 가장 좋은 툴이라고 한다.
이상치 감지 함수로, warning을 보내거나 심각성에 따라 pipeline을 중단할 수도 있다.
정말 중요한 작업 중 하나이다.
데이터 소실 뿐만 아니라, 실제 현업에서 서버 엔지니어가 로그 남기는 방식을 바꿨다든지, 데이터벨트 스키마가 바뀌었다든지 여러 상황에서 파이프라인이 깨질 수 있기 때문 --> 인지하지 못한 채 파이프라인이 깨질 수 있음
3. Data preprocessing
- 새로 수집한 데이터를 모델이 이해할 수 있는 형태로 변환
- 레이블은 다중 열 벡터로 변환 또는 텍스트 문자를 인덱스로 변환하거나 텍스트 토큰을 워드 벡터로 변환
Feature Engineering 진행
- Feature Space 늘리기
- 특정 Feature에 정규화 방법도 실험에 넣어서 autoML coverage를 넓히는 게 좋다 -> 효율적 성능 향상이 가능해짐
전처리는 Batch 단위로 한꺼번에 많이 해주는 것이 좋음 -> 이후 전처리데이터를 데이터로더에 캐싱할 수 있기 때문
4. Model training
- 모델 튜닝은 상당한 성능 개선과 경쟁 우위를 제공할 수 있다
- 머신러닝 파이프라인을 고려하기 전에 모델을 튜닝하도록 설정하거나 파이프라인의 일부를 이용하여 튜닝하는 것이 바람직하다고 한다.
- 모델 학습은 Computing 자원이 한정적이기 때문에, 훈련을 효율적으로 분포시키는 게 중요
- GPU가 여러 개일 때 AutoML을 어떻게 돌려야 할까
- Search Space가 고정된 상태에서, 성능이 saturation이 되는 순간이 오기에, Early Stopping을 고려해야 함
- Hyperparamter Optimization 외 여러가지 방법이 있음
5. Model analysis
- 일반적으로 정확도 또는 loss를 사용하여 최적의 모형 모수 집합을 결정
- 모델의 최종 버전을 결정한 후에는 모델의 성능에 대해 보다 심층적으로 분석하는 것이 유용함
- 다양한 metric을 이용해 계산하거나 학습에 사용되는 validation set보다 더 큰 데이터셋에서 test를 수행하는 등의 작업을 포함
- 모델 분석을 심층적으로 하는 이유는 모형의 예측이 공정하다는 것을 확인하기 위함.
최종적인 결과만 보는 게 아니라, 다차원 분석을 해주는 게 해당 단계
6. Model Validation
- 모델 버전 지정 및 검증 단계의 목적은 다음 버전으로 어떤 모델, 하이퍼 파라미터 세트 및 데이터셋이 선택되었는지 추적하는 것
- 모델 버전 관리 툴은 MLflow 등 여러 가지가 있음
- 사용한 데이터셋, 사용한 H.P, 성능 등을 기록
- Stage 관리(dev, staging, production 등)도 포함
- 일반적인 배포랑 달라서 트리거가 다름
- Training이 완료됐다고 무조건 배포를 하는 게 아님
7. Model Deployment
- REST, RPC, 프로토콜과 같은 여러 API인터페이스를 제공하여 동일한 모델의 여러 버전을 동시에 호스트할 수 있는 경우가 많음
- 여러 버전을 동시에 호스팅한다면 모델 A/B 테스트를 실행하면서 모델 개선 사항에 대한 피드백을 얻을 수 있다.
- 모델이 많아지면 관리를 못하게 됨
- 모델 배포 시스템, 모델 추론 결과를 피드백받는 과정이 정리 및 자동화가 잘 돼있어야 한다.
- 서빙하는 솔루션은 다양하게 있음
- 텐서플로 서빙, 토치서브 등 / 서빙 시 파이토치는 코드까지 같이 내야해서 별로다..
8. Feedback Loop
- 새로 배포된 모델의 효과와 성능을 측정하기 위함
- 배포한 인스턴스가 input으로 무엇이 들어왔고, 예측 결과들이 어떻게 됐는 지 등의 기록을 남겨주어야 함
- Inference 시, input 값과 inference 결과, Ground Truth를 받아놓으면 이것이 Serving Dataset이 된다.
- TFDB에 이 값을 넣어주어서 비교 가능
- Serving Data Distribution이 Train Data Distribution과 Data Drift가 많이 차이가 난다면, TFDB로 soft warning을 띄울 수 있다.
- 두 가지 수동 검토 단계(Model Analysis, Feedback)를 제외하고 전체 파이프라인을 자동화할 수 있다.
- Data Scientist가 기존 model을 update하고 유지하는 것이 아니라, 새로운 모델을 개발하는 데 집중할 수 있게끔
현업에서 Researcher와 협업 시, Researcher의 인사 평가는 new model development와 관련이 있다.
그래서 Service와 관련 없는 model을 만들어내는 경우가 있는데, 그래서 Service에 contiribution했을 때 좋은 평가를 받을 수 있다는 명확한 기준점이 있어야 함
개인 정보 보호
- 데이터 개인 정보 보호에 대한 고려사항은 표준 머신러닝 파이프라인 외부에 있음.
- 새로운 법률에 의해 개인 정보 보호 기법이 머신러닝 파이프라인을 구축하기 위한 도구로 통합됨
- 차등 개인 정보 보호, 연합 학습, 암호화된 머신 러닝, ...
기술적으로 해결할 수 있는 방법도 존재하지만, 기본적인 가이드라인을 지켜야 한다
물론 다 따르긴 쉽진 않지만, 고민을 해야 한다.
'IT_Study > Ops' 카테고리의 다른 글
| [MLOps] Docker 개념 및 흐름 간단 정리 (1) | 2023.10.31 |
|---|---|
| [MLOps] 코드 품질 관리(Quality Control) 관련 개념 (0) | 2023.10.30 |
| [MLOps] Kubeflow 개요 : 아키텍쳐 및 파이프라인 이해 (1) | 2023.10.27 |
| [MLOps] Machine Learning Pipeline에 대한 이해 (1) (2) | 2023.10.26 |
| [공통 PJT] Ubuntu에서 Jenkins와 GitLab 연동해서 CI 해보기 (with Docker) (0) | 2023.08.20 |